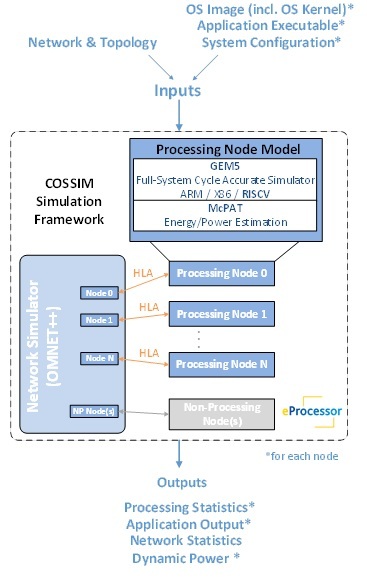
Kucza, N., Porrmann, F., Stollenwerk, C., & Hagemeyer, J. (2025). Efficient Edge AI for Next Generation Smart Mirror Applications. IEEE Access, 1-1. https://doi.org/10.1109/ACCESS.2025.3574492 June 10, 2025
Mika, K., Porrmann, F., Kucza, N., Griessl, R., & Hagemeyer, J. “RECS: A Scalable Platform for Heterogeneous Computing”. 2023 IEEE 36th International System-on-Chip Conference (SOCC),https://doi.org/10.1109/SOCC58585.2023.10256982 February 20, 2025
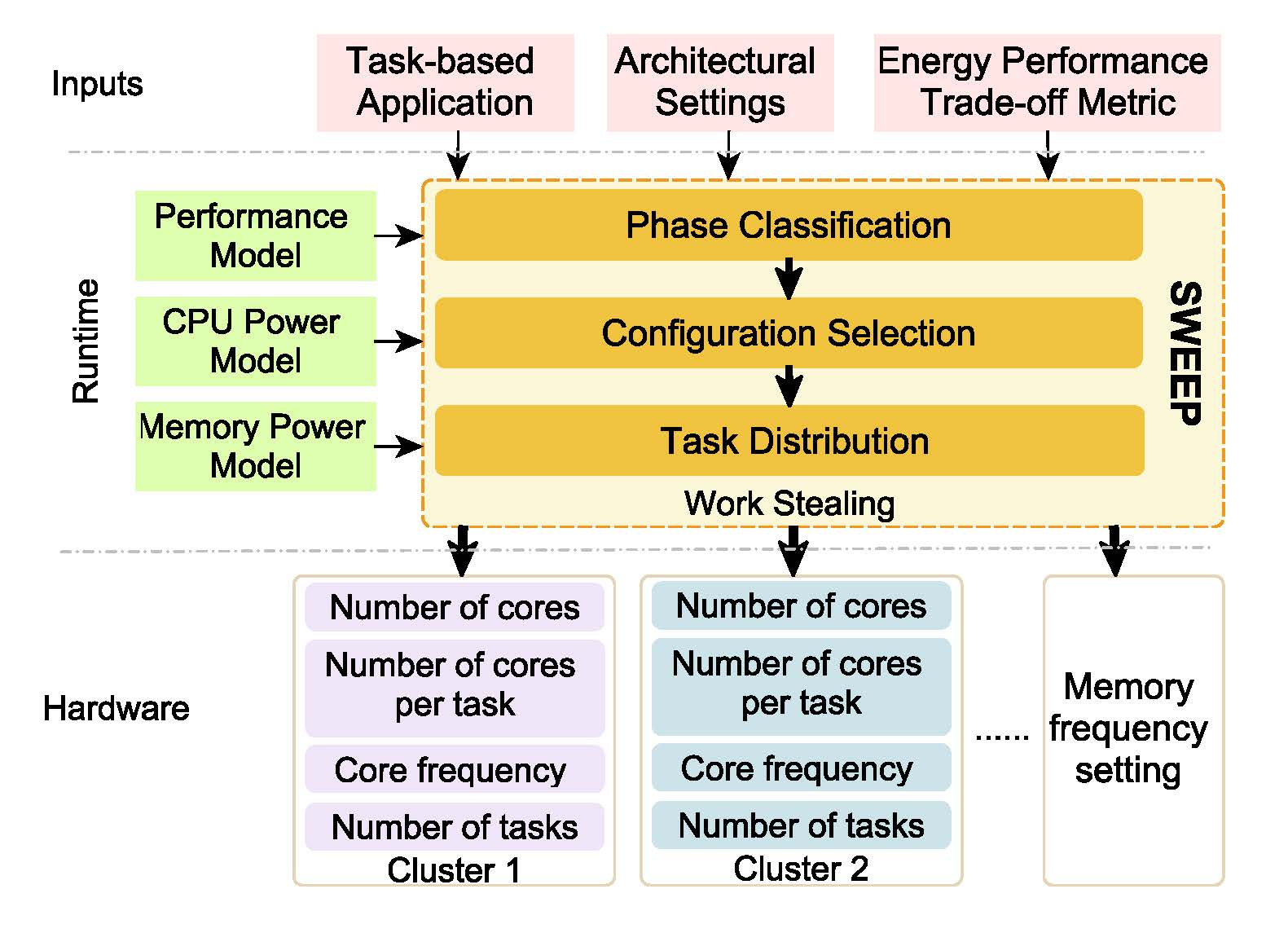
Jing Chen, Madhavan Manivannan, Bhavishya Goel and Miquel Pericàs, “SWEEP: Adaptive Task Scheduling for Exploring Energy Performance Trade-offs,” 2024 IEEE International Parallel and Distributed Processing Symposium (IPDPS), San Francisco, CA, USA, 2024, pp. 325-336, doi: 10.1109/IPDPS57955.2024.00036. November 1, 2024
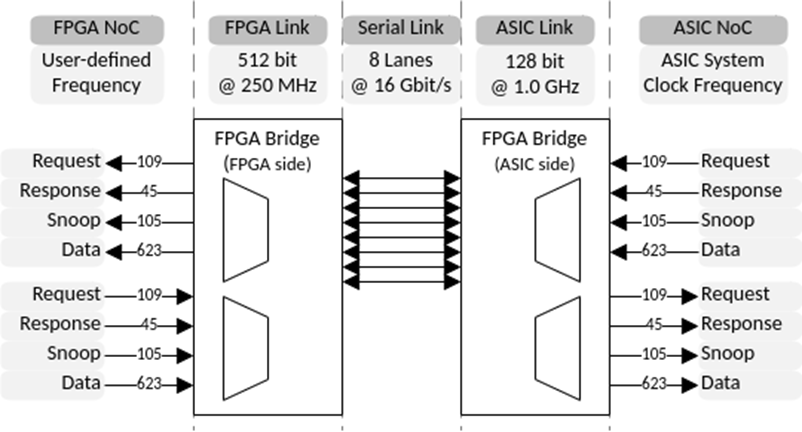
M. Vázquez, M. W. Azhar and P. Trancoso, “Exploiting the Potential of Flexible Processing Units,” 2023 IEEE 35th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), Porto Alegre, Brazil, 2023, pp. 34-45, doi: 10.1109/SBAC-PAD59825.2023.00013. November 14, 2023