Multi-core processors have become ubiquitous across domains ranging from embedded systems to data centers because of their ability to facilitate energy-efficient high performance computing. The architecture of a typical multi-core processor mainly comprises cores that are the computational workhorses, caches that act as buffers to reduce access latency to memory and an interconnection network that connects all the on chip components. Such architectures can typically be viewed as a shared memory multiprocessor wherein a group of cores share a common pool of memory (cache and main memory). This shared memory model simplifies the design of operating systems (OS), system software and applications since it lets programmers implicitly assume a coherent view of memory. In reality, the onus of providing a coherent view of memory is on the hardware and the eProcessor hardware is no different. Below we explain the basic concepts of cache coherence and give a glimpse of how it is handled in the eProcessor project.
Data incoherency: Let us consider an illustrative example of running a multi-threaded program on a system comprising two cores (C0,C1) with private caches connected to memory by a system bus as shown in Figure 1. Let’s assume that this system does not provide hardware support for maintaining coherence. At time T0, C0 issues a read access for address X. Since the read access results in a miss in the private cache of C0 a request is sent to memory. The memory responds with data which ends up being cached in the private cache of C0. At time T1, C1 tries to increment X. Since the address cannot be located in the private cache of C1, a request is sent to memory, data is fetched and inserted in the private cache. Then the value is incremented and this updated value is stored in the private cache of C1. Finally, at time T2, C0 reads address X . However, it ends up reading an incoherent copy of address X that is cached in C0.
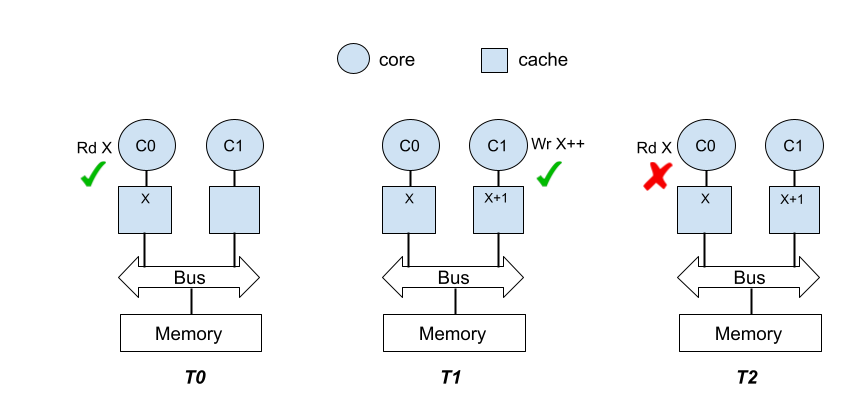
Figure1: Data incoherency without support for cache coherence
Hardware cache coherence: Most multi-core processors provide hardware support for ensuring coherence among copies of data that are retained in the caches. Ensuring coherence in simple terms entails that any read operation on an address returns the latest update made to that address. The popular strategy for ensuring coherence is the write invalidate strategy and has two requirements. Firstly, it requires a write operation to an address to remove local copies cached by other cores. Secondly, it requires a read operation to an address to fetch the latest update to that address. Let’s revisit the example discussed in Figure 1, assuming a system that ensures cache coherency. At time T1, when C1 writes to address X, the cache coherence mechanism will remove the copy of X in the cache of C0. At T2, when C0 reads address X, the updated value of address X from C1 will be fetched into the cache of C0 ensuring data coherence as shown in Figure 2. The hardware unit(s) that implements the functionality needed to ensure coherence is referred to as the coherence controller.
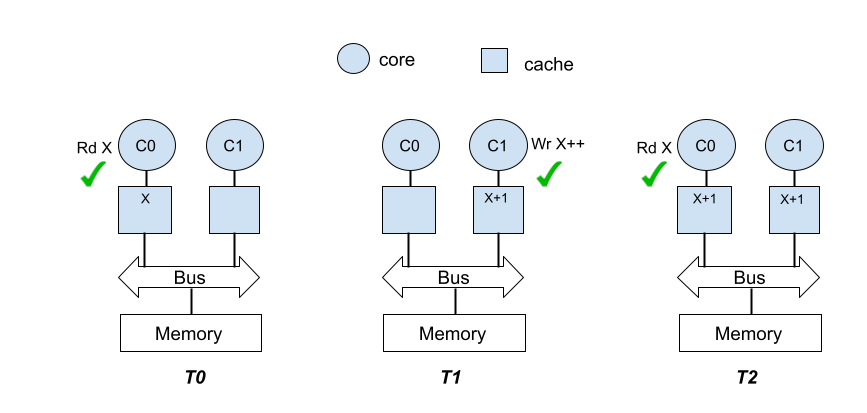
Figure2: Hardware support for cache coherence
eProcessor: The real-world implementations of hardware cache coherence are more complex than the design outlined above. The hardware needs to ensure data coherency across multi-level cache hierarchies while maintaining high throughput and scalability. However, the basic principles discussed above still apply. In the context of the eProcessor project, Chalmers will implement a write invalidate directory coherence protocol for ensuring coherence among multiple agents with different coherence requirements based on the ARM Coherent Hub Interconnect (CHI) specification. The two main types of coherence agents are the fully coherent RISC-V out-of-order cores and IO coherent AI/Bioinformatics accelerators.