The eProcessor vector accelerator design supports the IEEE754 double (64-bit) and single (32-bit) precision formats (FP64/32), the 16-bit “brain floating-point” format (BF16), and two different 8-bit format, 1-4-3 and 1-5-2, referred to as “Hybrid 8-bit Floating Point” (HFP8).

While the wider formats are appropriate for the traditional scientific applications, small precision floating point formats are gaining interest for AI computing [2] in particular the 1-5-2 and 1-4-3 [1,2]. Supporting HFP8 allows trans-precision computing in the same bit-width. Both commercial and research processors natively supporting HFP8 have recently been developed [3,4,5].
The eProcessor design also supports the conversion of values between the different formats (widening/narrowing conversions), and widening arithmetic operations where the operands are W bits wide and the results is 2*W bits wide (e.g. adding two FP8 vectors resulting in a BF16 vector).
All the different FP units are integrated under a common wrapper within the eProcessor vector accelerator. A high-level diagram of the units and the wrapper is depicted below.
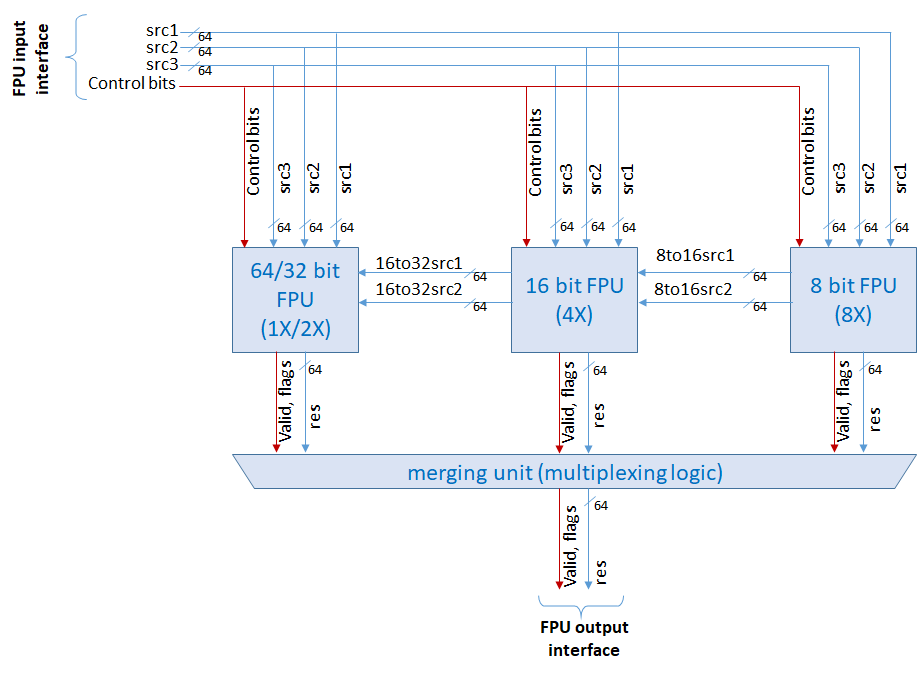
The interface of the FPU wrapper exported to the VPU is composed of four inputs: three 64-bit operands – namely src1, src2, and src3 – and the control bits. The output signals include control and flag bits as well as a 64-bit result value. Note the horizontal data flowing from right to left, which represents the values passed on a widening operation. The units instantiated in a single VPU lane are 1×64-bit, 2×32-bit FPUs, 4×16-bit BF16 FPUs, and 8×8-bit HFP8 FPUs.
The HFP8 unit supports all of the RISC-V standard vector floating-point operations on numbers with two different 8-bit formats, as defined below:
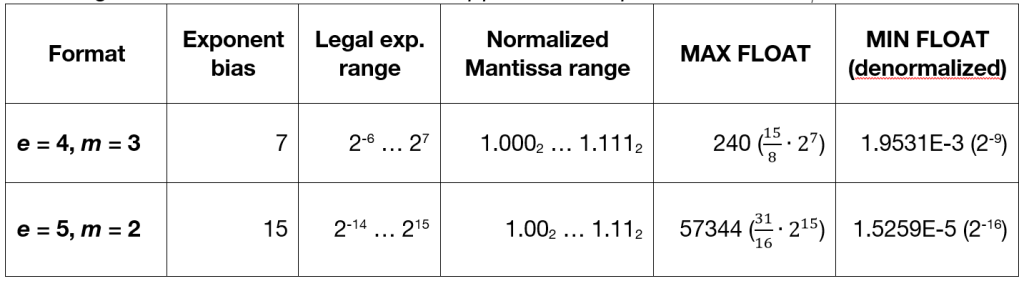
Encoding of normalized numbers in the supported 8-bit precision formats
Encoding of de-normal numbers in the supported 8-bit precision formats
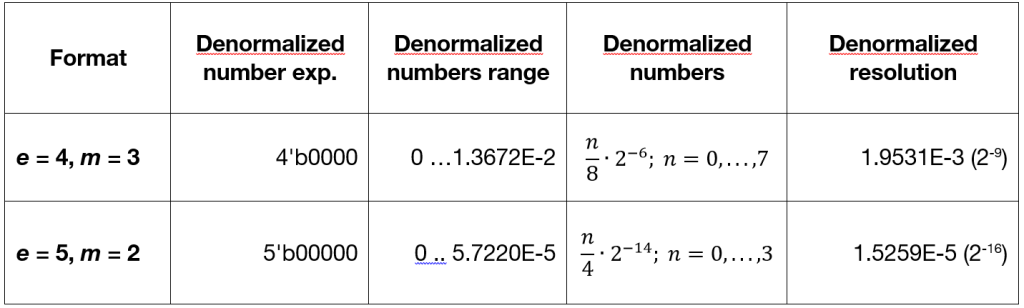
Although implementing non-standard formats, the policies to manage de-normal values, NaN, rounding modes, and exception conditions (flags) strictly follow all the indications of the IEEE754 standard for higher precision formats. Fused-multiply-add operations are supported with exact results according to the output format. A particular aspect of 8-bit floating point unit design is that, due to the very limited number of different values representable, supporting operations on de-normal numbers is an essential feature.
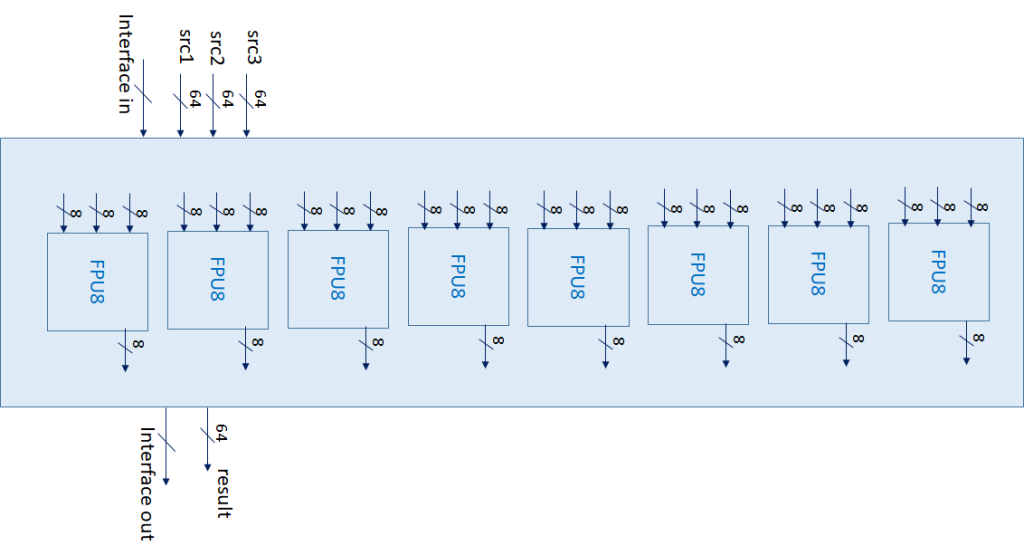
The present implementation of the 8xHFP8 unit in the eProcessor design completes any 8 operations in four clock cycles, yet it can produce 8 new results per clock cycle becausw all the operations are fully pipelined in four stages.
Since there is no standard open-source reference model for HFP8 operation, a C-language “golden model” has been developed and integrated in a dedicated testbench for functional verification purposes of the FP8 unit. The C model has also been integrated within the Spike simulator, which in turn is integrated in the Universal Verification Methodology (UVM) environment of the eProcessor design, so that the HFP8 arithmetic instructions can be directly verified within real application execution as well as dedicated benchmark programs.
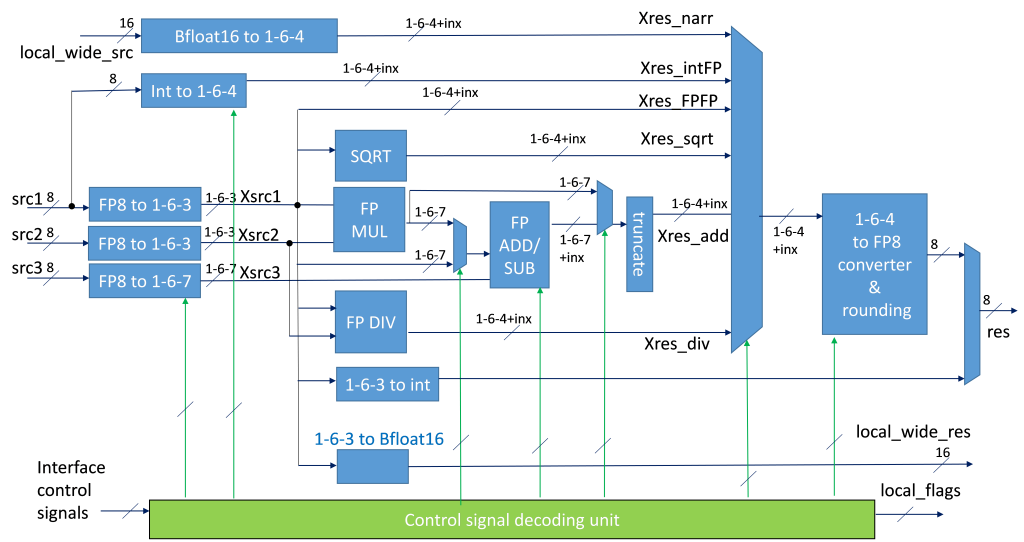
Differently from existing implementations of 8-bit FPUs, the eProcessor design is strongly tailored to the specific properties of the very limited number of bits involved in the operations, so that the internal structure of each of the 8 HFP8 units is composed of ad-hoc logic-arithmetic blocks. This allows optimizing the area and power in the view of highly parallel implementations. The source formats 1-4-3 and 1-5-2 are converted into an internal 1-6-3 format on which the logic-arithmetic processing is performed, and then converted back to the target format of the result. A simplified sketch of a single HFP8 unit is depicted below.
[2] Micikevicius, Paulius & Stosic, Dusan & Burgess, Neil & Cornea, Marius & Dubey, Pradeep & Grisenthwaite, Richard & Ha, Sangwon & Heinecke, Alexander & Judd, Patrick & Kamalu, John & Mellempudi, Naveen & Oberman, Stuart & Shoeybi, Mohammad & Siu, Michael & Wu, Hao. (2022). FP8 Formats for Deep Learning. 10.48550/arXiv.2209.05433.
[3] https://developer.nvidia.com/blog/nvidia-hopper-architecture-in-depth/
[4] Tortorella, Y., Bertaccini, L., Benini, L., Rossi, D., & Conti, F. (2023). RedMule: A Mixed-Precision Matrix-Matrix Operation Engine for Flexible and Energy-Efficient On-Chip Linear Algebra and TinyML Training Acceleration. arXiv preprint arXiv:2301.03904.
[5] S. K. Lee et al., “A 7-nm Four-Core Mixed-Precision AI Chip With 26.2-TFLOPS Hybrid-FP8 Training, 104.9-TOPS INT4 Inference, and Workload-Aware Throttling,” in IEEE Journal of Solid-State Circuits, vol. 57, no. 1, pp. 182-197, Jan. 2022, doi: 10.1109/JSSC.2021.3120113.